Reconocimiento Facial

Orígenes del reconocimiento facial
El reconocimiento facial automatizado es un concepto que se introdujo en la década de 1960. Fue entonces cuando se desarrolló el primer sistema semiautomático de reconocimiento facial, el cual requería la intervención de un operador para localizar rasgos (ojos, orejas, nariz y boca) en las fotografías, antes de que el sistema calculara las distancias a puntos de referencia comunes y comparara los datos.
En la década de 1970, Goldstein, Harmon y Lesk utilizaron 21 marcadores subjetivos específicos, como el color del cabello y el grosor de los labios, para automatizar el reconocimiento facial; sin embargo, estos marcadores seguían requiriendo un proceso manual. En 1988 se produjo un hito cuando Kirby y Sirovich aplicaron el análisis de componentes principales (PCA), una técnica estándar del álgebra lineal, al problema del reconocimiento facial, demostrando que eran necesarios menos de 100 valores para codificar la imagen de un rostro convenientemente alineado y normalizado.
En 1991, Turk y Pentland, utilizando la técnica de eigenfaces —como se denominó al método de Kirby y Sirovich—, demostraron que el error residual podía emplearse para detectar rostros en imágenes. Este descubrimiento permitió el desarrollo de sistemas de reconocimiento fiables en tiempo real. Si bien esta aproximación estaba algo limitada por factores ambientales, generó un interés significativo que impulsó desarrollos posteriores de estos sistemas.
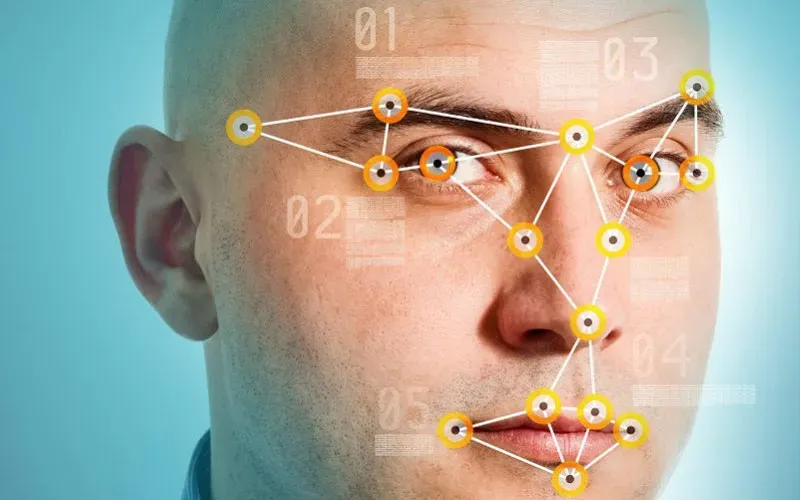
Captura de imagen en los sistemas de reconocimiento
En el estudio del reconocimiento facial pueden observarse dos enfoques predominantes: el geométrico (basado en rasgos) y el fotométrico (basado en lo visual). Como resultado de las investigaciones realizadas, han surgido diversos sistemas y algoritmos orientados al reconocimiento facial, que se diferencian principalmente por el proceso de captura de imágenes que requieren y por el procesamiento posterior que se realiza sobre ellas. En los apartados siguientes se explican las diferencias derivadas del método de captura de imágenes durante la fase de entrenamiento del sistema y la fase de reconocimiento.
Sistemas de reconocimiento facial 2D y 3D
Existe una gran variedad de métodos de reconocimiento facial que utilizan imágenes de intensidad en 2D (fotografías convencionales); sin embargo, el principal problema para su correcto funcionamiento es común y se debe a tres factores: la pose, la iluminación y la variación de la expresión facial. Cualquier cambio en alguno de estos elementos puede degradar el rendimiento del sistema. La variación de la pose puede modificar drásticamente la apariencia de un rostro y, en algunos casos, la diferencia puede ser mayor que la existente con el rostro de otra persona, lo que complica considerablemente el reconocimiento. Lo mismo ocurre con los cambios de iluminación y de expresión facial.
Algunas técnicas intentan solucionar estos problemas mediante una perspectiva 3D. La mayoría busca reconstruir modelos faciales tridimensionales a partir de múltiples imágenes de una misma persona, adquiridas mediante sistemas multicámara o directamente con dispositivos 3D, como láseres y escáneres. La ventaja de utilizar datos 3D (representaciones de imágenes de 180° en coordenadas cilíndricas) es que, además de la textura, se dispone de información de profundidad. Esto hace que el sistema de reconocimiento sea más robusto frente a variaciones de iluminación, pose y expresión, ya que la profundidad no cambia aunque estos aspectos visuales sí lo hagan.
No obstante, el principal inconveniente de estos métodos es la adquisición de datos 3D durante la fase de reconocimiento. La precisión de los algoritmos de reconstrucción tridimensional depende de los parámetros de adquisición, por lo que se requiere un entorno controlado en el que los componentes estén correctamente calibrados y sincronizados, además de la cooperación del individuo a reconocer. Estas condiciones pueden cumplirse durante la fase de entrenamiento, cuando la base de datos se construye o se amplía, pero no durante la fase de reconocimiento. La mayoría de las aplicaciones de seguridad y control de acceso se desarrollan en escenarios no controlados, donde normalmente solo se dispone de una fotografía o imagen 2D del sujeto a identificar.


